
The issue
There are a many tutorials describing how to auto-scale EC2 instances based on CPU Utilization or Memory Utilization of the host system. Similar approaches can be found to scale ECS Containers automatically based on the CPU/Memory metrics supported by default in ECS (see https://docs.aws.amazon.com/AmazonECS/latest/developerguide/cloudwatch-metrics.html). If your ECS tasks/containers process messages in a SQS queue (e.g. Laravel Queue Workers), you can still use CPU or Memory metrics as an indication for scaling in and out. In my opinion it’s much more reliable and significant if you scale in/out based on the number of messages waiting in the SQS queue to be processed. In this post I’m describing how to do Auto-scaling of ECS Containers based on SQS queue metrics.
The solution
As a starting point I used the tutorial from AWS at https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-using-sqs-queue.html AWS describes how to auto-scale EC2 instances based on SQS. In my case I’m scaling ECS tasks.
define IAM User Permissions
Af first I created an IAM User to access and modify the relevant AWS resources. You can use the following IAM policy for this user. Just replace the placeholder for the AWS Region, AWS Account ID, ECS Cluster Name, ECS Service Name and your SQS Queue Name:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecs:UpdateService",
"ecs:DescribeServices",
"sqs:GetQueueAttributes"
],
"Resource": [
"arn:aws:ecs:eu-central-1:123456789:service/My-ECS-Cluster/My-ECS-Service",
"arn:aws:sqs:eu-central-1:123456789:my-sqs-queue"
]
},
{
"Effect": "Allow",
"Action": [
"ecs:ListServices",
"cloudwatch:PutMetricData",
"ecs:ListTasks",
"ecs:DescribeServices",
"cloudwatch:GetMetricStatistics",
"ecs:DescribeTasks",
"cloudwatch:ListMetrics",
"ecs:DescribeClusters",
"ecs:ListClusters"
],
"Resource": "*"
}
]
}
Publish SQS queue Metrics to CloudWatch
At first we need to track the number of messages waiting in the SQS queue to be processed. For this I coded the following bash script:
#!/bin/bash
AWS_ACCOUNT_ID=${1:-123456789}
SQS_QUEUE_NAME=${2:-My-SQS-Queue}
ECS_CLUSTER=${3:-My-ECS-Cluster}
ECS_SERVICE=${4:-My-ECS-Service}
CW_METRIC=${5:-BacklogPerECSTask}
CW_NAMESPACE=${6:-ECS-SQS-Autoscaling}
CW_DIMENSION_NAME=${7:-SQS-Queue}
CW_DIMENSION_VALUE=${8:-My-SQS-Queue}
ApproximateNumberOfMessages=$(aws sqs get-queue-attributes --queue-url https://sqs.$AWS_DEFAULT_REGION.amazonaws.com/$AWS_ACCOUNT_ID/$SQS_QUEUE_NAME --attribute-names All | jq -r '.[] | .ApproximateNumberOfMessages')
echo "ApproximateNumberOfMessages: " $ApproximateNumberOfMessages
NUMBER_TASKS=$(aws ecs list-tasks --cluster $ECS_CLUSTER --service-name $ECS_SERVICE | jq '.taskArns | length')
echo "NUMBER_TASKS: " $NUMBER_TASKS
MyBacklogPerWorker=$((($ApproximateNumberOfMessages / $NUMBER_TASKS) + ($ApproximateNumberOfMessages % $NUMBER_TASKS > 0)))
echo "MyBacklogPerWorker: " $MyBacklogPerWorker
# send average number of current backlogs of the workers as a custom Metric to CloudWatch
aws cloudwatch put-metric-data --metric-name $CW_METRIC --namespace $CW_NAMESPACE \
--unit None --value $MyBacklogPerWorker --dimensions $CW_DIMENSION_NAME=$CW_DIMENSION_VALUE
In the beginning some variables are defined. You can pass the variables as arguments to the bash script and define default values in case you call the script without arguments. I won’t explain each of them in detail because they should be self-explanatory. The most important points are:
You get the number of messages available for retrieval from the SQS queue via the CLI command get-queue-attributes (see https://docs.aws.amazon.com/cli/latest/reference/sqs/get-queue-attributes.html) Using the json tool jq allows us to easily extract the needed value ApproximateNumberOfMessages from the json formatted result.
The metric ApproximateNumberOfMessages can not be found in the SQS metrics. You only get this value via CLI command. Unfortunately I didn’t find any information how AWS calculates this value. In my impression it’s somehow calculated using the metrics NumberOfMessagesSent and ApproximateNumberOfMessagesVisible which are available via the AWS Management Console, CLI and API.
In the next step we calculate the current backlog of our ECS tasks (in my case called workers as I coded this for Laravel queue workers). ApproximateNumberOfMessages is divided by the current number of running ECS tasks which we get via the command ecs list-tasks. The result is saved in the variable MyBacklogPerWorker and this value is pushed to the custom Cloudwatch Metric via the CLI Command put-metric-data (see https://docs.aws.amazon.com/cli/latest/reference/cloudwatch/put-metric-data.html).
I decided to run the bash script every 1 minute via a cronjob (see later section explaining the Docker container).
Calculate Backlogs and Scale in/OUT based on CloudWatch Metrics
I’m using the size of the backlog per task/worker as a threshold for scaling in or out. I defined the variable LATENCY and PROCESSING_TIME. LATENCY is the maximum allowed number of seconds till a message from the SQS queue should be processed (queue delay). PROCESSING_TIME is the average number of seconds an ECS task needs for processing a message from the SQS queue. Deviding those two values defines the allowed backlog per ECS task/worker. In the code snippet below 10 (20/2=10) messages is the maximum of messages one ECS task should need to process.
LATENCY=${1:-20} # maximum allowed latency (seconds) for processing a message
PROCESSING_TIME=${2:-2} # average number of seconds to process an image
backlog_per_worker_allowed=$(($LATENCY / $PROCESSING_TIME)) # number of messages a worker can process within the allowed latency timeframe
I’m running the second bash script (shown below) every 5 minutes. It will get the custom CloudWatch metric send by the first bash script for the last 20 minutes from now and calculate the average backlog for all currently running ECS tasks. If the average value of the backlog for all currently running ECS tasks is higher than the defined threshold we will scale out.
The whole bash script looks like:
#!/bin/bash
LATENCY=${1:-20} # maximum allowed latency (seconds) for processing a message
PROCESSING_TIME=${2:-2} # average number of seconds to process an image
ECS_CLUSTER=${3:-My-ECS-Cluster}
ECS_SERVICE=${4:-My-ECS-Service}
CW_METRIC=${5:-BacklogPerECSTask}
CW_NAMESPACE=${6:-ECS-SQS-Autoscaling}
CW_DIMENSION_NAME=${7:-SQS-Queue}
CW_DIMENSION_VALUE=${8:-My-SQS-Queue}
MAX_LIMIT_NUMBER_QUEUE_WORKERS=${9:-200}
ceil() {
if [[ "$1" =~ ^[0-9]+$ ]]
then
echo $1;
return 1;
fi
echo "define ceil (x)
{if (x<0) {return x/1} \
else {if (scale(x)==0) {return x} \
else {return x/1 + 1 }}} ; ceil($1)" | bc
}
backlog_per_worker_allowed=$(($LATENCY / $PROCESSING_TIME)) # number of messages a worker can process within the allowed latency timeframe
echo "backlog_per_worker_allowed: " $backlog_per_worker_allowed
# get backlogs of the worker for the last 10 minutes
export LC_TIME=en_US.utf8
CF_JSON_RESULT=$(aws cloudwatch get-metric-statistics --namespace $CW_NAMESPACE --dimensions Name=$CW_DIMENSION_NAME,Value=$CW_DIMENSION_VALUE --metric-name $CW_METRIC \
--start-time "$(date -u --date='5 minutes ago')" --end-time "$(date -u)" \
--period 60 --statistics Average)
echo "CF_JSON_RESULT: " $CF_JSON_RESULT
# sum up the average values of the last 10 minutes
SUM_OF_AVERAGE_CW_VALUES=$(echo $CF_JSON_RESULT | jq '.Datapoints | .[].Average' | awk '{ sum += $1 } END { print sum }')
echo "SUM_OF_AVERAGE_VALUES: " $SUM_OF_AVERAGE_CW_VALUES
# count the number of average values the CW Cli command returned (varies between 4 and 5 values)
NUMBER_OF_CW_VALUES=$(echo $CF_JSON_RESULT | jq '.Datapoints' | jq length)
echo "NUMBER_OF_CW_VALUES: " $NUMBER_OF_CW_VALUES
# calculate average number of backlog for the workers in the last 10 minutes
AVERAGE_BACKLOG_PER_WORKER=$(echo "($SUM_OF_AVERAGE_CW_VALUES / $NUMBER_OF_CW_VALUES)" | bc -l )
echo "AVERAGE_BACKLOG_PER_WORKER: " $AVERAGE_BACKLOG_PER_WORKER
# calculator factor to scale in/out, then ceil up to next integer to be sure the scaling is sufficient
FACTOR_SCALING=$(ceil $(echo "($AVERAGE_BACKLOG_PER_WORKER / $backlog_per_worker_allowed)" | bc -l) )
echo "FACTOR_SCALING: " $FACTOR_SCALING
# get current number of ECS tasks
CURRENT_NUMBER_TASKS=$(aws ecs list-tasks --cluster $ECS_CLUSTER --service-name $ECS_SERVICE | jq '.taskArns | length')
echo "CURRENT_NUMBER_TASKS: " $CURRENT_NUMBER_TASKS
# calculate new number of ECS tasks, print leading 0 (0.43453 instead of .43453)
NEW_NUMBER_TASKS=$( echo "($FACTOR_SCALING * $CURRENT_NUMBER_TASKS)" | bc -l | awk '{printf "%f", $0}')
echo "NEW_NUMBER_TASKS: " $NEW_NUMBER_TASKS
## we run more than enough workers currently, scale in slowly by 20 %
if [ $FACTOR_SCALING -le "1" ];
then
NEW_NUMBER_TASKS=$( echo "(0.8 * $CURRENT_NUMBER_TASKS)" | bc -l)
fi;
echo "NEW_NUMBER_TASKS: " $NEW_NUMBER_TASKS
# round number of tasks to int
NEW_NUMBER_TASKS_INT=$( echo "($NEW_NUMBER_TASKS+0.5)/1" | bc )
if [ ! -z $NEW_NUMBER_TASKS_INT ];
then
if [ $NEW_NUMBER_TASKS_INT == "0" ];
then
NEW_NUMBER_TASKS_INT=1 # run at least one worker
fi;
if [ $NEW_NUMBER_TASKS_INT -gt $MAX_LIMIT_NUMBER_QUEUE_WORKERS ];
then
NEW_NUMBER_TASKS_INT=$MAX_LIMIT_NUMBER_QUEUE_WORKERS # run not more than the maximum limit of queue workers
fi;
fi;
echo "NEW_NUMBER_TASKS_INT:" $NEW_NUMBER_TASKS_INT
# update ECS service to the calculated number of ECS tasks
aws ecs update-service --cluster $ECS_CLUSTER --service $ECS_SERVICE --desired-count $NEW_NUMBER_TASKS_INT 1>/dev/null
There have been some issues I want to mention:
- I needed to set the environment variable LC_TIME to en_US.utf8 in order to get the right output from the unix commands date -u and date -u –date=’10 minutes ago’ when calling the CLI command aws cloudwatch get-metric-statistics for the last 10 minutes.
- I used the tool bc (Basic Calculator) to do math operations like division from floating point numbers
- the bash function ceil() at the beginning of the script rounds up floating point number to the next larger integer (if the argument is already an integer, it just returns the argument)
- FACTOR_SCALING is calculated by dividing the currently calculated average backlog per ECS task by the allowed backlog per ECS task, it’s rounded up to the next larger integer using the function ceil():
FACTOR_SCALING=$(ceil $(echo "($AVERAGE_BACKLOG_PER_WORKER / $backlog_per_worker_allowed)" | bc -l) )
- the new number of ECS tasks is calculated by the product of the FACTOR_SCALING and the currently running number of ECS tasks CURRENT_NUMBER_TASKS:
NEW_NUMBER_TASKS=$( echo "($FACTOR_SCALING * $CURRENT_NUMBER_TASKS)" | bc -l | awk '{printf "%f", $0}')
- this value is rounded to an integer
echo "($NEW_NUMBER_TASKS+0.5)/1" | bc
- There is an edge case you have to take care: when FACTOR_SCALING is 1 it means the we run enough ECS tasks at the moment, so we should scale in. Otherwise we would keep running the same amount of ECS tasks forever and would never scale in as FACTOR_SCALING is always at least 1 (see above point, FACTOR_SCALING is rounded up to the next higher integer which means >= 1). In this case I defined to scale in by 20%:
## we run more than enough workers currently, scale in slowly by 20 % if [ $FACTOR_SCALING -le "1" ]; then NEW_NUMBER_TASKS=$( echo "(0.8 * $CURRENT_NUMBER_TASKS)" | bc -l) fi;
- I added a variable MAX_LIMIT_NUMBER_QUEUE_WORKERS which is used as the maximum number of queue workers running at the same time. I’m using this as a security measure in case my script fails somehow and wants to start way to many workers (which could be expensive).
if [ $NEW_NUMBER_TASKS_INT -gt $MAX_LIMIT_NUMBER_QUEUE_WORKERS ];
then
NEW_NUMBER_TASKS_INT=$MAX_LIMIT_NUMBER_QUEUE_WORKERS # run not more than the maximum limit of queue workers
fi;
- after all these calculations we call the AWS CLI command aws ecs update-service to update the ECS service to the new number of ECS tasks, only errors are printed to stdout to avoid the huge default output from this CLI command:
# update ECS service to the calculated number of ECS tasks aws ecs update-service --cluster $ECS_CLUSTER --service $ECS_SERVICE --desired-count $NEW_NUMBER_TASKS_INT 1>/dev/null
Run the bash Scripts via Cron in a Docker Container
To run the first bash script called publish-Backlog-per-Worker.sh every 1 minute and the second bash script called scaling.sh every 10 minutes I created a Docker container for it (which itself is running as an ECS task). The Dockerfile looks like:
FROM alpine:latest
LABEL maintainer="https://allaboutaws.com"
ARG DEBIAN_FRONTEND=noninteractive
USER root
RUN apk add --update --no-cache \
jq \
py-pip \
bc \
coreutils \
bash
# update pip
RUN pip install --upgrade pip
RUN pip install awscli --upgrade
# Configure cron
COPY ./docker/workers/scaling/crontab /etc/cron/crontab
# Init cron
RUN crontab /etc/cron/crontab
WORKDIR /code/
COPY ./docker/workers/scaling/scaling.sh /code/
COPY ./docker/workers/scaling/publish-Backlog-per-Worker.sh /code
COPY ./docker/workers/scaling/entrypoint.sh /etc/app/entrypoint
RUN chmod +x /etc/app/entrypoint
ENTRYPOINT /bin/sh /etc/app/entrypoint
EXPOSE 8080
It’s an alpine container in which the necessary tools jq, bc, coreutils (for command date), bash and aws cli are installed.
The entrypoint file starts the cron daemon:
#!/bin/sh set -e crond -f
The file crontab which is copied inside the container (Don’t forget to put a new line at the end of this file! Cronjob needs it!):
*/10 * * * * /bin/bash /code/scaling.sh $LATENCY $PROCESSING_TIME $ECS_CLUSTER $ECS_SERVICE $CW_METRIC $CW_NAMESPACE $CW_DIMENSION_NAME $CW_DIMENSION_VALUE $MAX_LIMIT_NUMBER_QUEUE_WORKERS * * * * * /bin/bash /code/publish-Backlog-per-Worker.sh $AWS_ACCOUNT_ID $SQS_QUEUE_NAME $ECS_CLUSTER $ECS_SERVICE $CW_METRIC $CW_NAMESPACE $CW_DIMENSION_NAME $CW_DIMENSION_VALUE
As you can see the arguments for the bash scripts are environment variables. I set them when starting the container.
How to build the Docker container
docker build -t ecs-autoscaling-sqs-metrics:latest -f ./Cronjob.Dockerfile .
How to run the Docker Container
docker run -it -e AWS_DEFAULT_REGION=eu-central-1 -e AWS_ACCESS_KEY_ID=XXX -e AWS_SECRET_ACCESS_KEY=XXX -e AWS_ACCOUNT_ID=XXX -e LATENCY=20 -e PROCESSING_TIME=2 -e SQS_QUEUE_NAME=My-SQS-Queue -e ECS_CLUSTER=My-ECS-Cluster -e ECS_SERVICE=My-ECS-Service -e CW_METRIC=MyBacklogPerTask -e CW_NAMESPACE=ECS-SQS-Scaling -e CW_DIMENSION_NAME=SQS-Queue -e CW_DIMENSION_VALUE=My-SQS-Queue -e MAX_LIMIT_NUMBER_QUEUE_WORKERS=200 ecs-autoscaling-sqs-metrics:latest
If you want to run this Docker Container as an ECS task, too, you can use this task definition using the prebuild docker image from DockerHub:
{
"family": "queue-worker-autoscaling",
"networkMode": "bridge",
"taskRoleArn": "arn:aws:iam::123456789:role/ecsTaskRole",
"containerDefinitions": [
{
"name": "cronjob",
"image": "sh39sxn/ecs-autoscaling-sqs-metrics:latest",
"memoryReservation": 256,
"cpu": 512,
"essential": true,
"portMappings": [{
"hostPort": 0,
"containerPort": 8080,
"protocol": "tcp"
}],
"environment": [{
"name": "AWS_DEFAULT_REGION",
"value": "eu-central-1"
},{
"name": "AWS_ACCESS_KEY_ID",
"value": "XXX"
},{
"name": "AWS_SECRET_ACCESS_KEY",
"value": "XXX"
},{
"name": "AWS_ACCOUNT_ID",
"value": "123456789"
},{
"name": "SQS_QUEUE_NAME",
"value": "My-SQS-Queue"
},{
"name": "LATENCY",
"value": "20"
},{
"name": "PROCESSING_TIME",
"value": "2"
},{
"name": "ECS_CLUSTER",
"value": "MY-ECS-CLUSTER"
},{
"name": "ECS_SERVICE",
"value": "My-QUEUE-WORKER-SERVICE"
},{
"name": "CW_METRIC",
"value": "BacklogPerECSTask"
},{
"name": "CW_NAMESPACE",
"value": "ECS-SQS-Autoscaling"
},{
"name": "CW_DIMENSION_NAME",
"value": "SQS-Queue"
},{
"name": "CW_DIMENSION_VALUE",
"value": "My-SQS-Queue"
},{
"name": "MAX_LIMIT_NUMBER_QUEUE_WORKERS",
"value": "200"
}],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/Queue-Worker-Autoscaling",
"awslogs-region": "eu-central-1",
"awslogs-stream-prefix": "ecs"
}
}
}
]
}
I added a logging configuration for CloudWatch Logs. This makes it easier to track and debug the algorithm. Don’t forget to create the CloudWatch log group /ecs/Queue-Worker-Autoscaling before starting the ECS task. Otherwise it will fail because the log group has to exist before you start the ECS task which pushes log to it.
Results
Using an example timeframe I show you how the auto-scaling of ECS containers based on SQS metrics works at the end.
The following screenshot shows the metric ApproximateNumberOfMessagesVisible which is significant for the current workload.
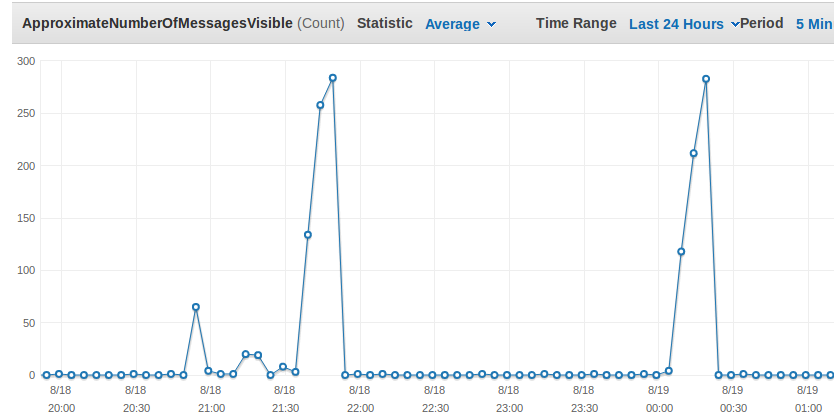
Above you can see two peaks at around 23:50 and 2:20. The custom metric showing the current Backlog per ECS Task fits to it as you see here:

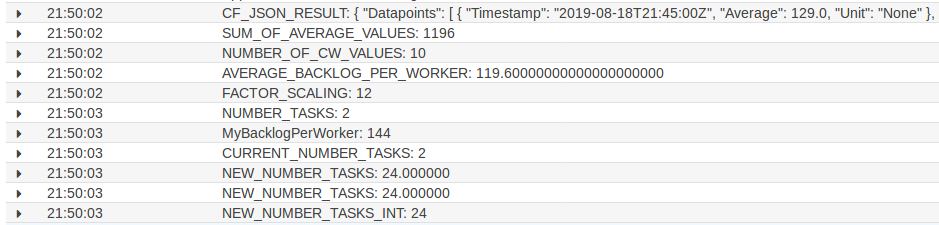
The CloudWatch Logs from the Cronjob ECS Tasks shows that the algorithm recognized that the average backlog per worker is too high and the number of workers is increased from 2 to 24.
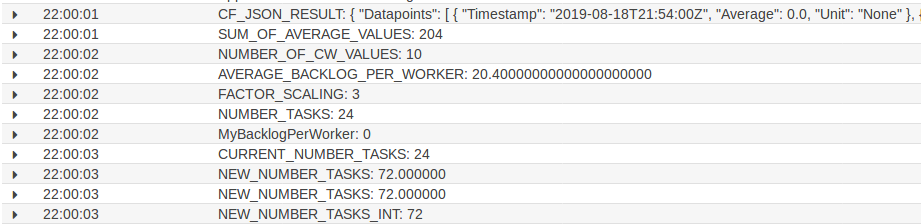
10 minutes later the script checks again the average backlog per ECS Task and again scales in as the it’s still too high:
Here you can see a graphical representation of the number of ECS Tasks:

You can see how the number of ECS Tasks increased and then descreased in steps by 20% as defined in the bash script.
External Links
I uploaded the files to my GitHub Repo at https://github.com/sh39sxn/ecs-autoscaling-sqs-metrics and the prebuild Container is saved in my DockerHub Repo at https://hub.docker.com/r/sh39sxn/ecs-autoscaling-sqs-metrics.